The papers findings show some impressive advances in applying reinforcement learning to complicated problems.
It’s free, every week, in your inbox.
Some scientists describe reinforcement learning as the first computational theory of intelligence.

In both cases, the AI systems were able to outmatch human world champions at their respective games.
But reinforcement learning systems are also notoriously renowned for their lack of flexibility.
Even slight changes to the original game will considerably degrade the AI models performance.

Humans, on the other hand, are very good at transferring knowledge across domains.
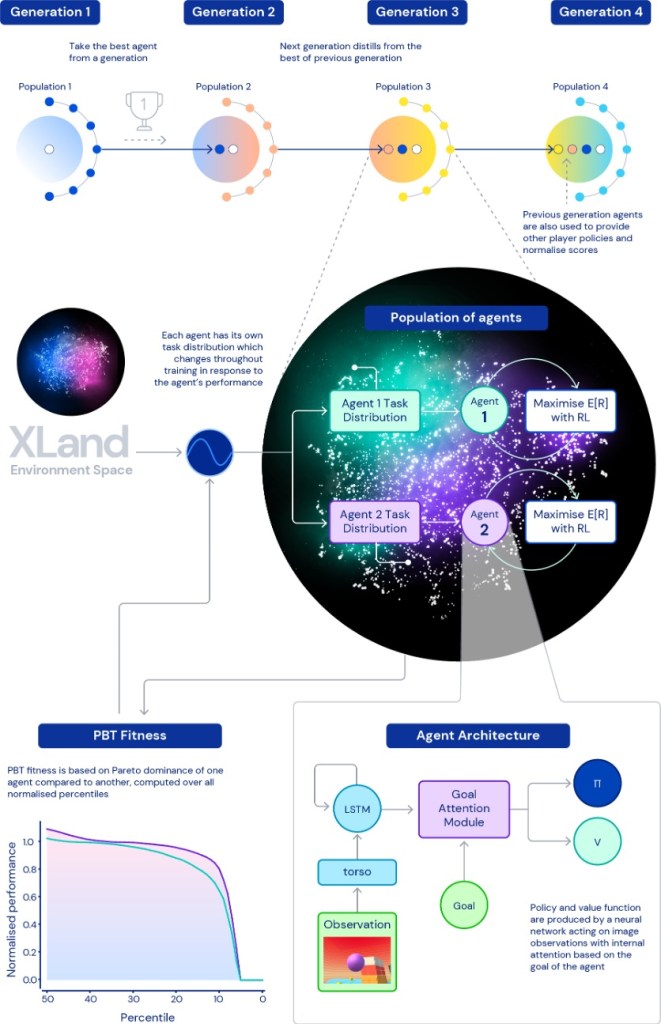
Some of the games include cooperation or competition elements involving multiple agents.
Each agent finetunes the parameters of its policy neural web link to maximize its rewards on the current task.
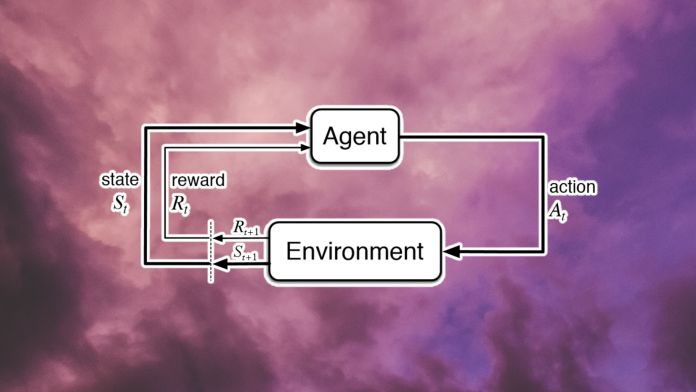
Once the agent masters its current challenge, the computational task generator creates a new challenge for the agent.
Some of the test tasks include well-known challenges such as capture the flag and hide and seek.
And the results were seeing clearly exhibit general, zero-shot behaviour across the task space.

Zero-shot machine learningmodels can solve problems that were not present in their training dataset.
If proven, this can be an important milestone.
Deep learning systems are often criticized for learning statistical correlationsinstead of causal relations.
But those are big ifs, and DeepMinds researchers are cautious about jumping to conclusions on their findings.
Suchfundamental self-learned skillsare another one of the highly sought goals of the artificial intelligence community.
And the skills it learns in accomplishing one thing can generalize to other goals.

That is very similar to how human intelligence is applied.
Nicholson also believes that other aspects of the papers findings hint at progress toward general intelligence.
Parents will recognize that open-ended exploration is precisely how their toddlers learn to move through the world.
They take something out of a cupboard, and put it back in.
They invent their own small goalswhich may seem meaningless to adultsand they master them, he said.
Overall, XLand is simply more of the same.
And this is basically how natural evolution has deliveredhuman and animal intelligence.
The XLand experiment has extended the same notion to a much greater level by adding the zero-shot learning element.
DeepMinds reinforcement learning agents might have become the masters of the virtual XLand.
But their simulated world doesnt even have a fraction of the intricacies of the real world.
That gap will continue to remain a challenge for a long time.
you might read the original articlehere.
