Codex powers Copilot, an AI pair programmer tool developed jointly by OpenAI and GitHub.
Copilot is currently available in beta test mode to a limited number of users.
The complexity ofdeep learning modelsis often measured by the number of parameters they have.

In general, a models learning capacity increases with the number of parameters.
GPT-3 was trained on more than 600 gigabytes, more than 50 times larger than GPT-2s training dataset.
It’s free, every week, in your inbox.

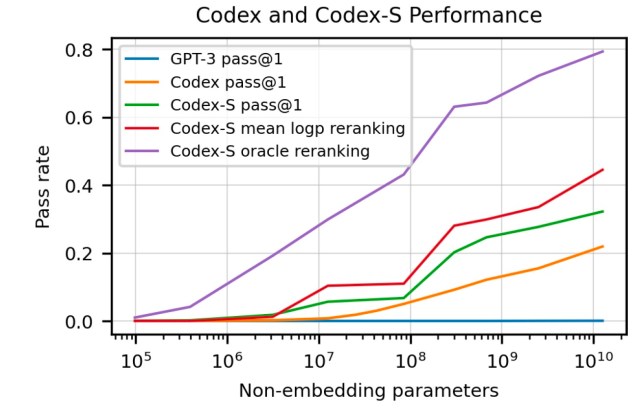
Opesolved 11.4 percent of the coding problems.
In other words, machine learning models are more accurate when they are designed to solve one specific problem.
On the other hand, when their problem domain is broadened, their performance decreases.
Wouldnt training the larger model on the Codex training data yield better results?
One probable reason for stopping at 12 billion could be the dataset size.
A larger Codex model would need a larger dataset.

Gathering and maintaining larger datasets is an expensive and time-consuming process.
An equally vexing problem would be the cost of Codex.
Finally, as OpenAIs experiments show, Codexs size/performance ratio follows a logarithmic scale.
This means that performance gains gradually reduce as you increase the size of the model.
And note that code generation is a very lucrative market.
Like all otherdeep learningbased language models, Codex is capturing statistical correlations between code fragments.
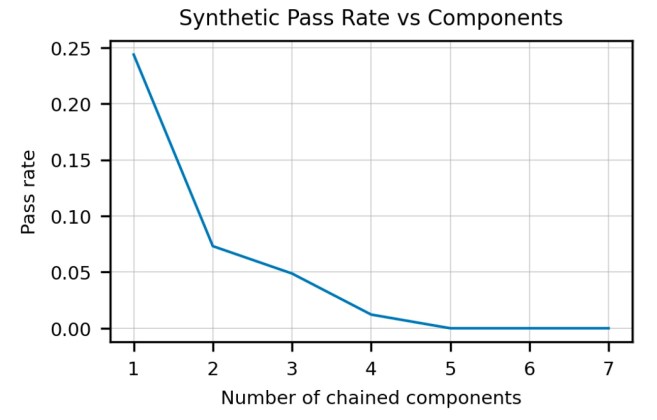
This is a scheme that works well when you want to solve simple problems that recur time and again.
Codex uses the contents of the file youre working on as context to generate its output.
Misalignment is an interesting phenomenon that needs further study.
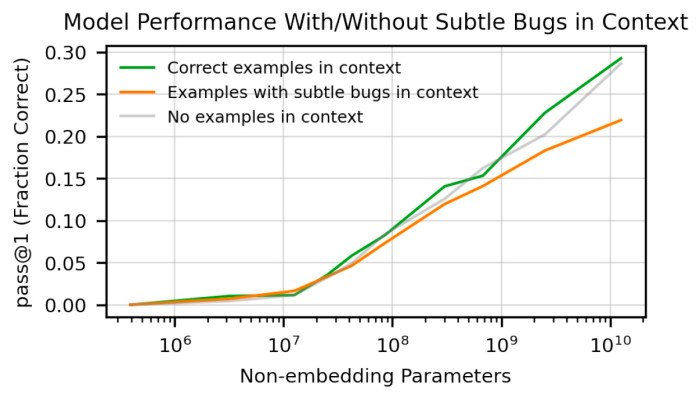
Codex is not a programmer.
And its also not going to take your job (if youre a programmer).
Coding is just part of what programmers do.
Given the obvious and subtle mistakes Codex can make, overlooking this threat can entail quality and security risks.
it’s possible for you to read the original articlehere.
