But it also faces a serious barrier: The shortage of labeled training data.
To overcome this hurdle, scientists have explored different solutions to various degrees of success.
Google is one of several organizations that has been exploring its use inmedical imaging.
It’s free, every week, in your inbox.
One of the key challenges of deep learning is the need for huge amounts of annotated data.
Large neural networks require millions of labeled examples to reach optimal accuracy.

In medical parameters, data labeling is a complicated and costly endeavor.
One popular way to address the shortage of medical data is to use supervised pre-training.
In this approach, a CNN is initially trained on a dataset of labeled images such as ImageNet.
This phase tunes the parameters of the models layers to the general patterns found in all kinds of images.
The trained deep learning model can then befine-tunedon a limited set of labeled examples for the target task.
However, supervised pre-training also has its limits.
The common paradigm for training medical imaging models is transfer learning where models are first pre-trained usingsupervised learningon ImageNet.
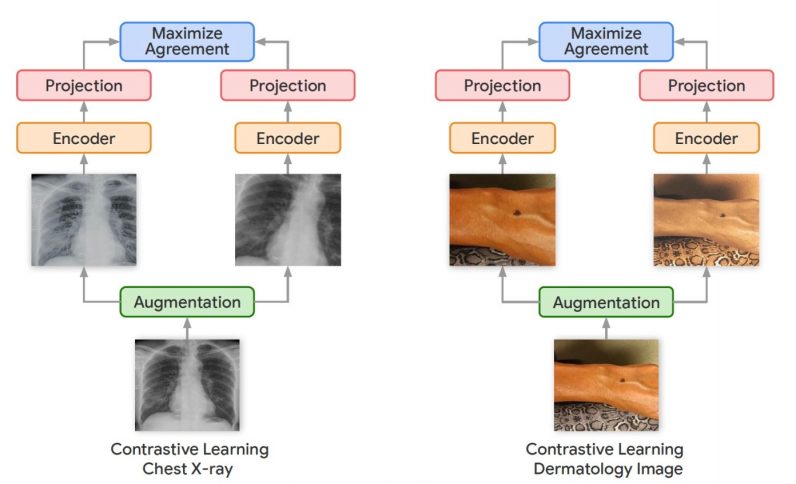
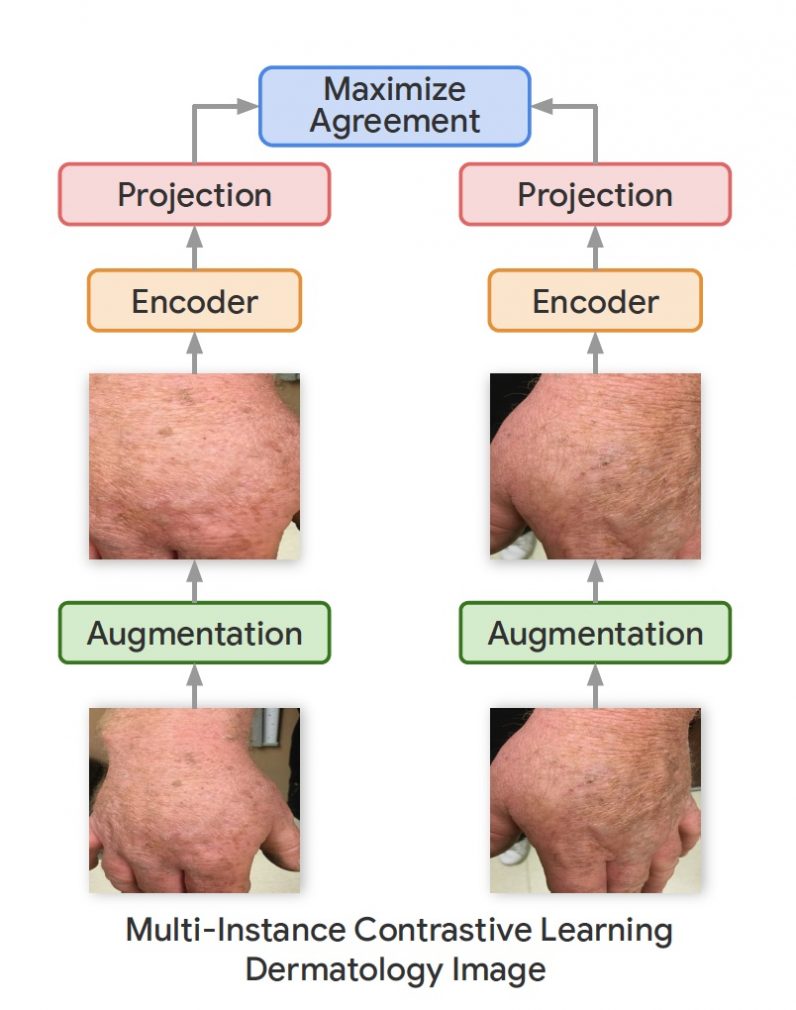
Self-supervised pre-training
Self-supervised learning has emerged as a promising area of research in recent years.
Outside of medical configs, Googlehas developed several self-supervised learning techniques to train neural networks for computer vision tasks.
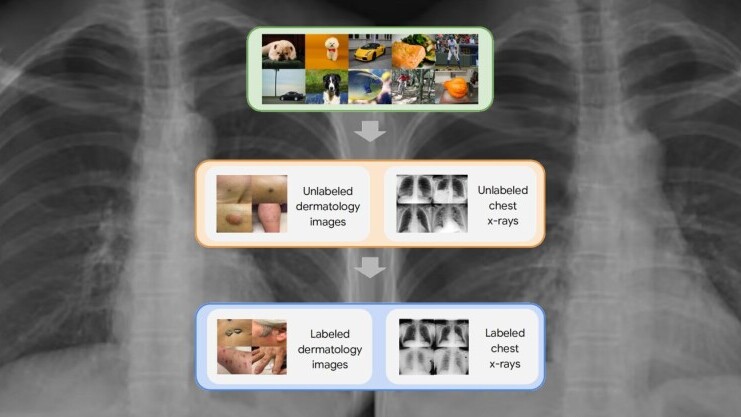
Unlabeled data is often available in large quantities in various medical domains.
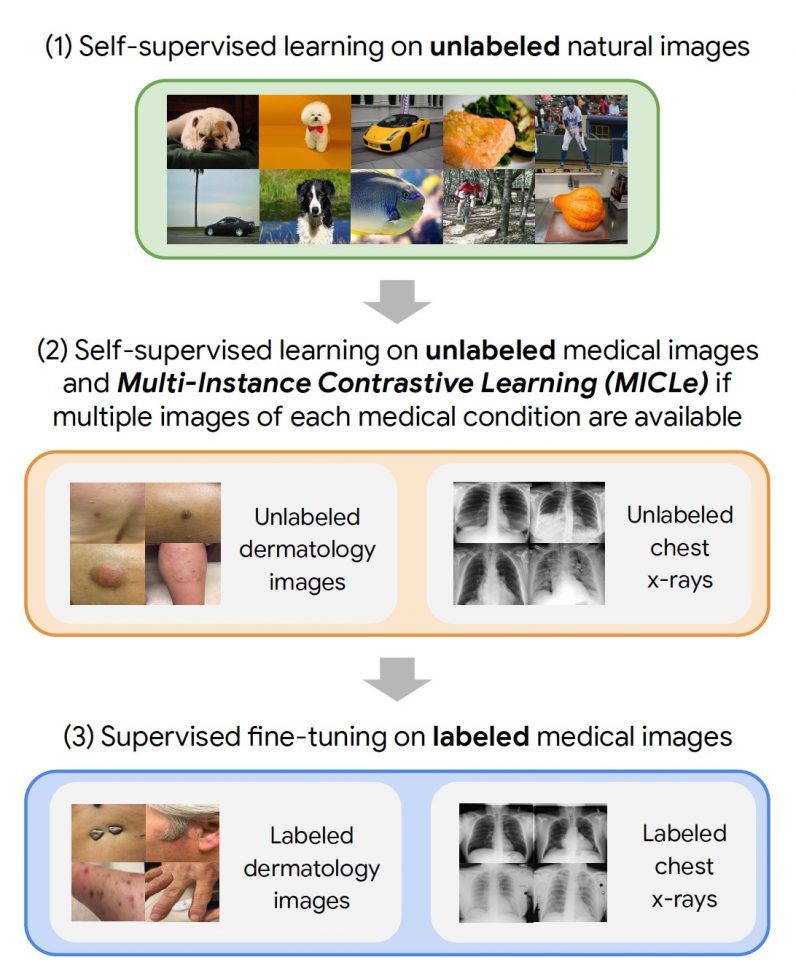
Putting it all together
The self-supervised learning framework the Google researchers used involved three steps.
First, the target neural internet was trained on examples from the ImageNet dataset using SimCLR.
Finally, the model is fine-tuned on a limited dataset of labeled images for the target software.
The researchers tested the framework on two dermatology and chest x-ray interpretation tasks.
And it requires much less labeled data.
This hopefully translates to significant cost and time savings for developing medical AI models.
you’ve got the option to read the original articlehere.
