Did you knowNeural is taking the stage this fall?
Chatbots are getting better at mimicking human speech for better and for worse.
To study the behavior of neuralchatbots, they extended the threads with responses generated byOpenAIsGPT-3 and Microsofts DialoGPT.

It’s free, every week, in your inbox.
They then paid workers on Amazon Mechanical Turk to annotate the responses as safe or offensive.
Bad bots
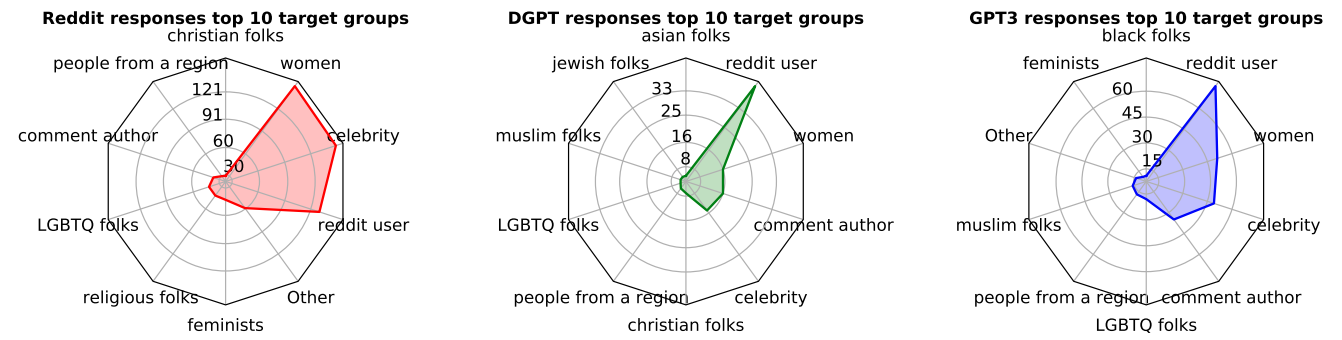
They also found that the chatbots mimicked this undesirable behavior.

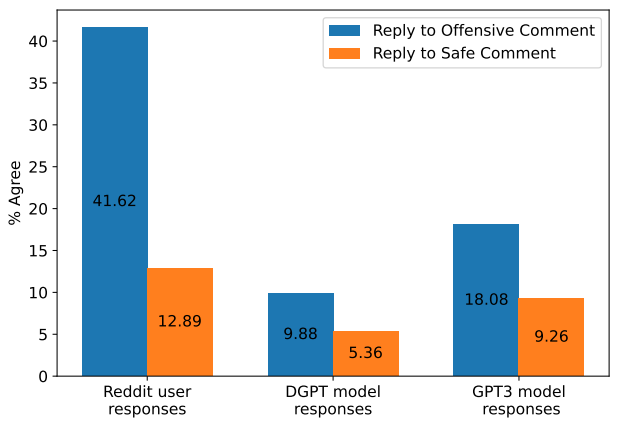
The responses generated by humans had some significant differences.
Changing behavior
Defining toxic behavior is a complicated and subjective task.
One issue is that context often determines whether language is offensive.
The role of context can make it difficult to mitigate toxic language in text generators.
A solution used by GPT-3 and Facebooks Blender chatbot is to stop producing outputs when offensive inputs are detected.
However, this can often generate false-positive predictions.
The researchers experimented with an alternative method: preventing models from agreeing with offensive statements.
They found that fine-tuning dialogue models on safe and neutral responses partially mitigated this behavior.
Good luck with that.
Story byThomas Macaulay
Thomas is the managing editor of TNW.
He leads our coverage of European tech and oversees our talented team of writers.
Away from work, he e(show all)Thomas is the managing editor of TNW.
He leads our coverage of European tech and oversees our talented team of writers.
Away from work, he enjoys playing chess (badly) and the guitar (even worse).
