Deep neural networks have gained fame for their capability to process visual information.
And in the past few years, they have become a key component of manycomputer vision applications.
Among the key problems neural networks can solve is detecting and localizing objects in images.
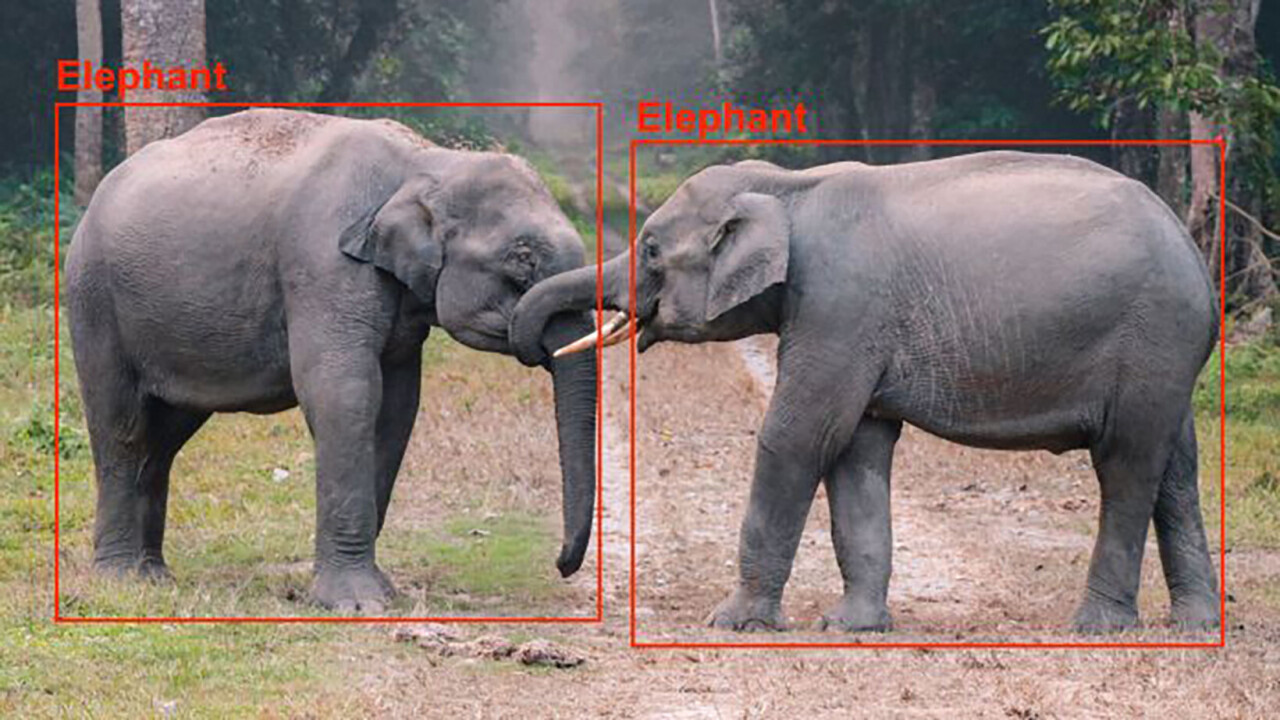
Object detection is used in many different domains, includingautonomous driving, video surveillance, and healthcare.
In this post, I will briefly review thedeep learning architecturesthat help computers detect objects.
This makes CNNs especially good for images, though they are used to process other types of data too.

40% off TNW Conference!
Each filter has different values and extracts different features from the input image.
The output of a convolution layer is a set of feature maps.
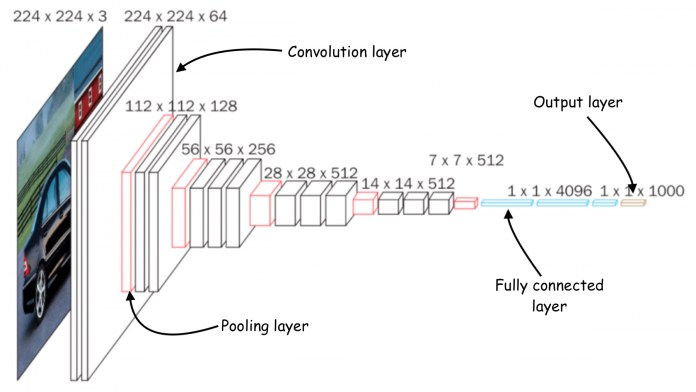
When stacked on top of each other, convolutional layers can detect a hierarchy of visual patterns.
The next layers can detect more complex patterns such as grids and circles.
This operation halves the size of the maps and keeps the most relevant features.
Pooling layers enable CNNs to generalize their capabilities and be less sensitive to the displacement of objects across images.
you’re able to always create and test your own convolutional neural connection from scratch.
Object detection networks bear much resemblance to image classification networks and use convolution layers to detect visual features.
In fact, most object detection networks use an image classification CNN and repurpose it for object detection.
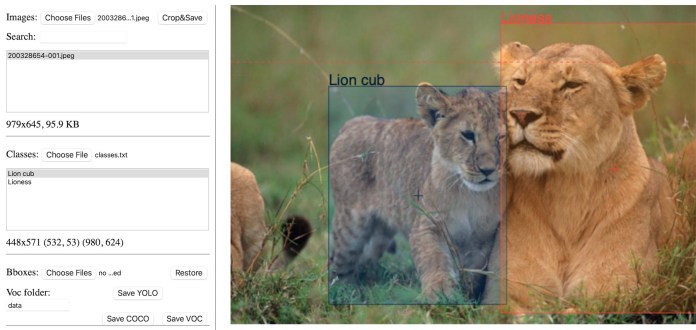
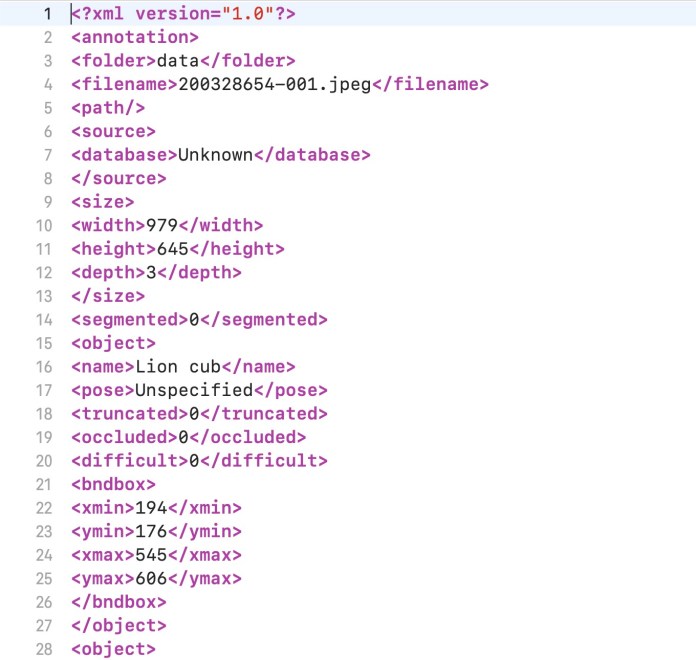
Object detection is asupervised machine learningproblem, which means you must train your models on labeled examples.
There are several open-source tools that create object detection annotations.
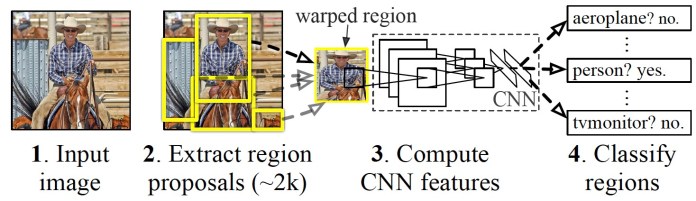
Now lets look at a few object-detection neural internet architectures.
The R-CNN is composed of three key components.
The region selector generates around 2,000 regions of interest for each image.

Next, the RoIs are warped into a predefined size and passed on to a convolutional neural online grid.
The CNN processes every region separately extracts the features through a series of convolution operations.
The CNN uses fully connected layers to encode the feature maps into a single-dimensional vector of numerical values.
Finally, a classifier machine learning model maps the encoded features obtained from the CNN to the output classes.
The classifier has a separate output class for background, which corresponds to anything that isnt an object.
R-CNN suffers from a few problems.
Second, the model must compute the features for each of the 2,000 regions separately.
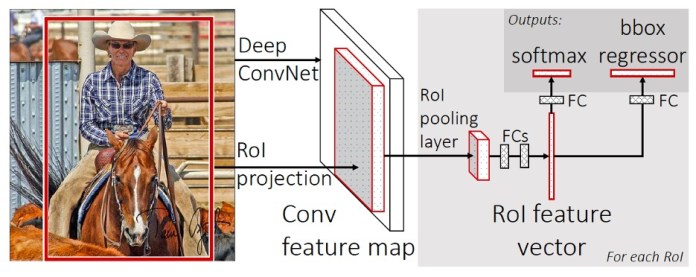
Fast R-CNN brings feature extraction and region selection into a single machine learning model.
This resulted in a significant boost in speed.
However, one issue remained unsolved.
Fast R-CNN still required the regions of the image to be extracted and provided as input to the model.
Fast R-CNN was still not ready for real-time object detection.
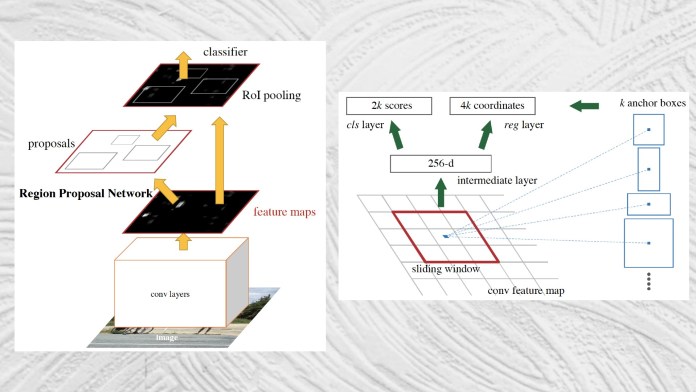
Faster R-CNN takes an image as input and returns a list of object classes and their corresponding bounding boxes.
The architecture of Faster R-CNN is largely similar to that of Fast R-CNN.
The proposed regions are then passed to the RoI pooling layer.
The rest of the process is similar to Fast R-CNN.
By integrating region detection into the main neural internet architecture, Faster R-CNN achieves near-real-time object detection speed.
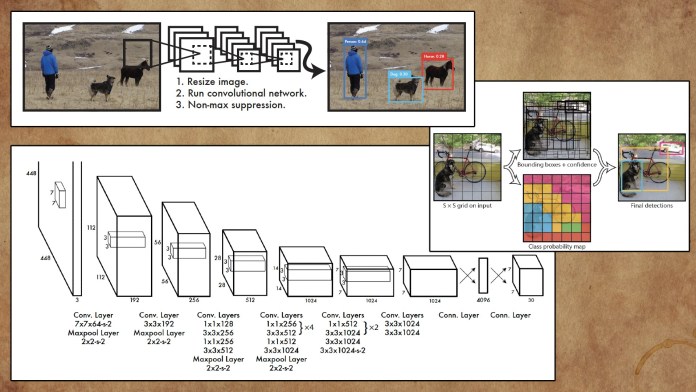
YOLO can perform object detection at video streaming frame rates and is suitable applications that require real-time inference.
Today, many applications use object-detection networks as one of their main components.
Its in your phone, computer, car, camera, and more.
you’re free to read the original articlehere.
