For instance, the famous BERT model has about ~110 million.
It’s free, every week, in your inbox.
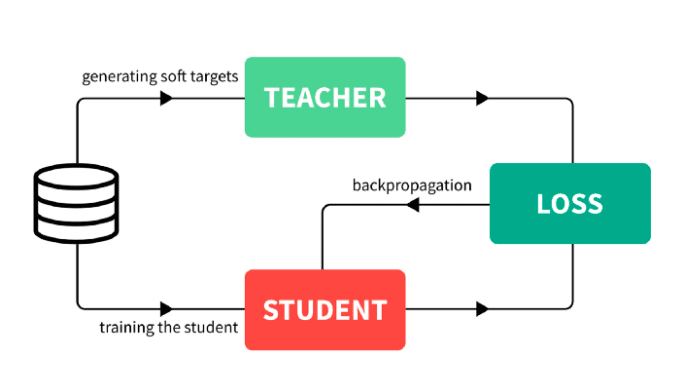
So, what is knowledge distillation?

Lets imagine a very complex task, such as image classification for thousands of classes.
Often, you cant just slap on a ResNet50 and expect it to achieve 99% accuracy.
So, you build an ensemble of models, balancing out the flaws of each one.
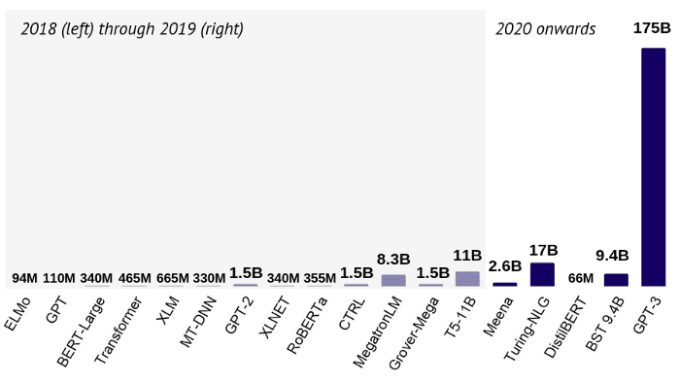
In broad strokes, the process is the following.
To visualize the process, you’ve got the option to think of the following.
Lets focus on the details a bit.

How is the knowledge obtained?
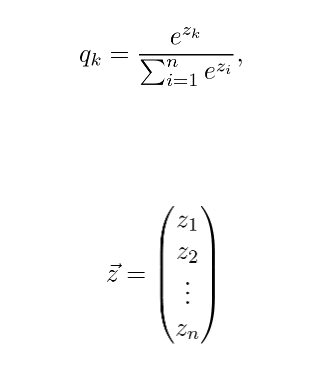
Instead of these, a slightly modified version is used:
WhereTis a hyperparameter calledtemperature.
These values are calledsoft targets.
IfTis large, the class probabilities are softer, that is, they will be closer to each other.
In the extreme case, whenTapproaches infinity,
IfT = 1, we obtain the softmax function.
For our purposes, the temperature is set to higher than 1, thus the namedistillation.
Why not train a small connection from the start?
You might ask, why not train a smaller internet from the start?
Wouldnt it be easier?
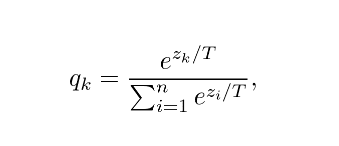
Sure, but itwouldnt worknecessarily.
Empirical evidence suggests that more parameters result in better generalization and faster convergence.
For complex problems, simple models have trouble learning to generalize well on the given training data.
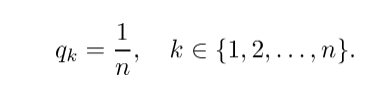
This benefits us in two ways.
They showed that distilling indeed helped a little, although even simpler neural networks have outperformed them.
However, a straightforward two-layer deep convolutional internet still reached 99.21% accuracy.

Thus, there is a trade-off between performance and explainability.
Distilling BERT
So far, we have only seen theoretical results instead of practical examples.
To change this, lets consider one of the most popular and useful models in recent years: BERT.
Originally published in the paperBERT: Pre-training of Deep Bidirectional Transformers for Language Understandingby Jacob Devlin et al.
from Google, it soon became widely used for various NLP tasks like document retrieval or sentiment analysis.
It was a real breakthrough, pushing state of the art in several fields.

There is one issue, however.
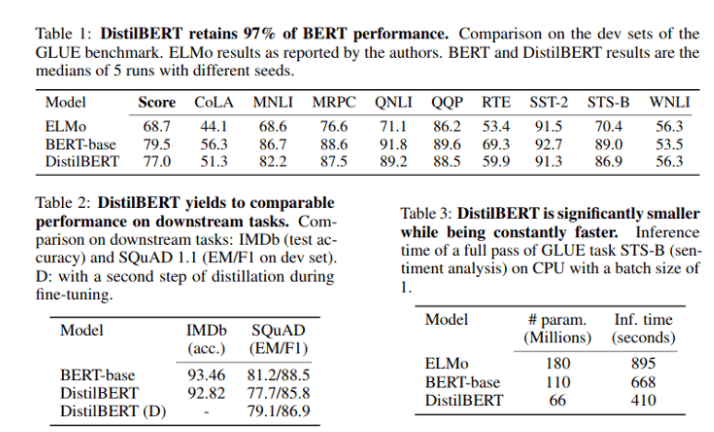
BERT contains ~110 million parameters and takes a lot of time to train.
The authors reported that the training required 4 days using 16 TPU chips in 4 pods.

One successful attempt to reduce the size and computational cost of BERT was made byHugging Face.
The smaller architecture requires much less time and computational resources: 90 hours on 8 16GB V100 GPUs.
This is a fantastic read, so I strongly recommend you to do so.
Rather, it uses the original model to train a smaller one called thestudent model.
This article was originally published byTivadar DankaonTowards Data Science.
it’s possible for you to read the original piecehere.
