When I was young, I always hated being namedDale.
Neither of these Dales fit my aspirational self-image.
On the contrary, I wanted to be named Sailor Moon.

I did not like that my name was androgynous 14 male Dales are born for every one female Dale.
When I asked my parents about this, their rationale was:
A.
Women with androgynous names arepotentially more successful.

Their hipster friends just named their daughter Dale and it wasjustso cute!
40% off TNW Conference!
[Read:Trouble with your tennis serves and penalty kicks?
I wouldnt want to leave that responsibility to taste or chance or trends.
Of course not Id turn to deep learning (duh!).
:
My child will be born in New Jersey.
She will grow up to be a software developer at Google who likes biking and coffee runs.
If you want to try this model out yourself, take a lookhere.
But still wouldnt it be cool to have the first baby named by an AI?
Happily, I found just that kind of datasethere, in a Github repo calledwikipedia-biography-datasetby David Grangier.
The dataset contains the first paragraph of 728,321 biographies from Wikipedia, as well as various metadata.
I also only considered names for which I had at least 50 biographies.
This left me with 764 names, majority male.
The most popular name in my dataset was John, which corresponded to 10092 Wikipedia bios (shocker!
), followed by William, David, James, George, and the rest of the biblical-male-name docket.
So the bio above becomes:
Alvin is a fictional character in the Fox animated series…
This is the input data to my model, and its corresponding output label is Dale.
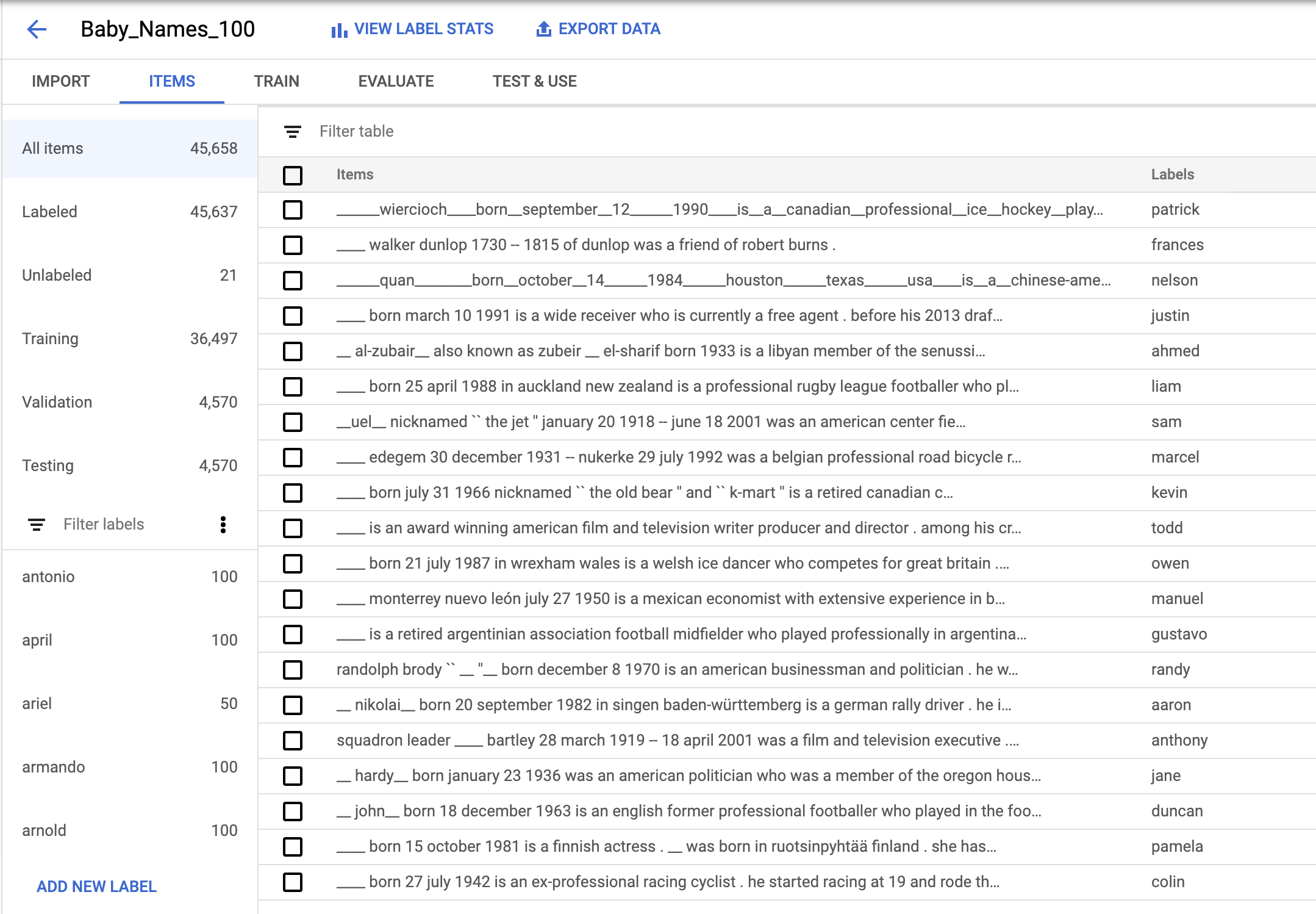
Once I prepared my dataset, I set out to build a deep learning language model.
To train a model, I navigated to the Train tab and clicked Start Training.
Around four hours later, training was done.
So how well did the name generator model do?
In this case, my model had a precision of 65.7% and a recall of 2%.
But in the case of our name generator model, these metrics arent really that telling.
Names are largely arbitrary, which means no model can make really excellent predictions.
My goal was not to build a model that with 100% accuracy could predict a persons name.
I just wanted to build a model that understoodsomethingabout names and how they work.
Its a useful way to debug or do a quick sanity check.
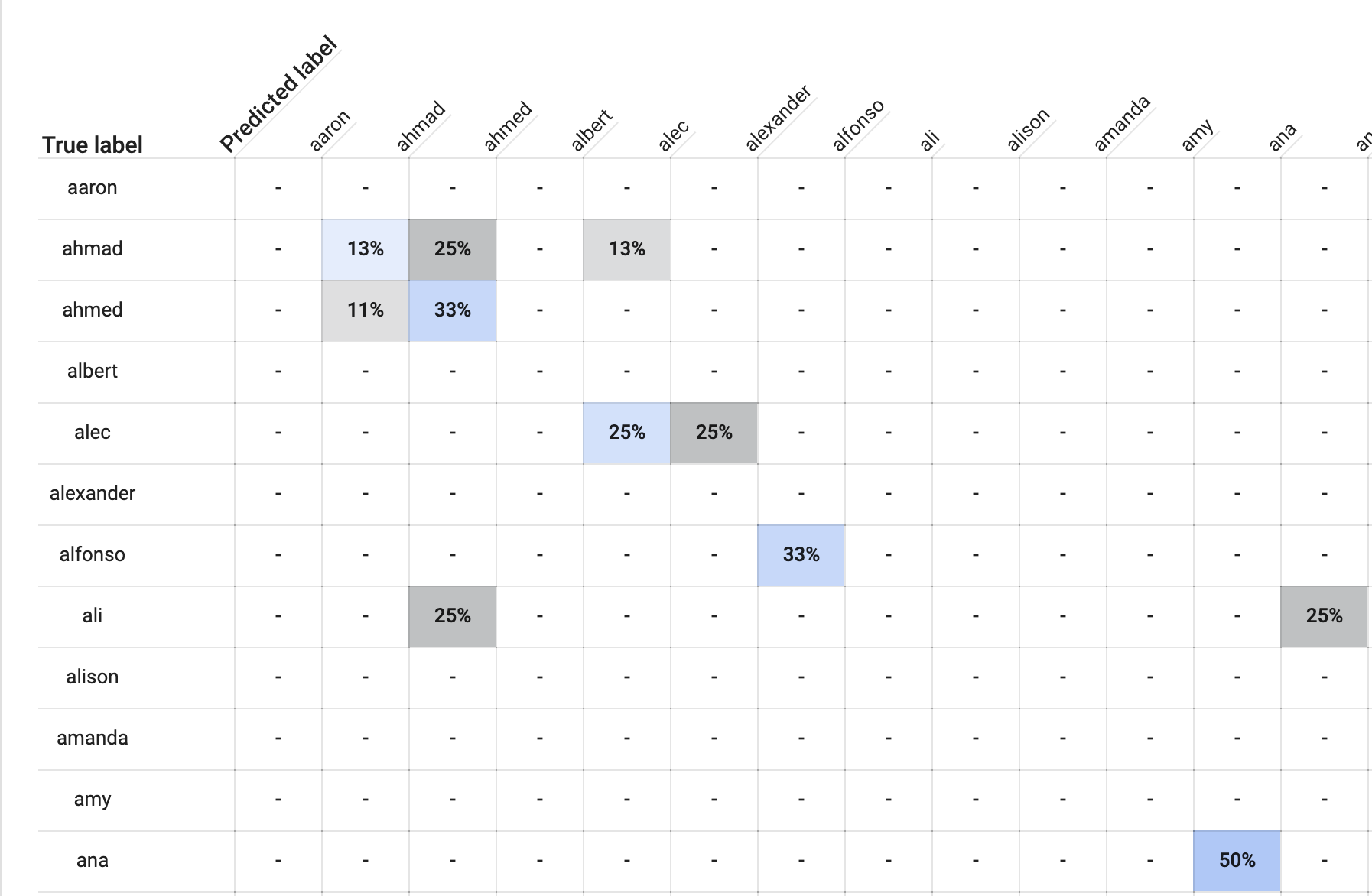
In the Evaluate tab, AutoML provides a confusion matrix.
So for example, take a look at therowlabeled ahmad.
Youll see a light blue box labeled 13%.
Another 13% of people named Ahmad were incorrectly labeled alec.
Same thing for people named Alec.
Seems like a good sign.
For the sentence He likes to eat, the top names were Gilbert, Eugene, and Elmer.
So it seems the model understands some concept of gender.
Next, I thought Id test whether it was able to understand how geography played into names.
Armando
She was born in Mexico Irene
He was born in France.
Gilbert
She was born in France.
Gilbert, Frances).
This tells me I didnt have enough global variety in my training dataset.
Model bias
Finally, I thought Id test for one last thing.
model, especially if your training dataset isnt reflective of the population youre building that model for.
Lets see if Im right:
They will be a computer programmer.
Joseph
They will be a nurse.
Frances
They will be a doctor.
Albert
They will be an astronaut.
Raymond
They will be a novelist.
Robert
They will be a parent.
Jose
They will be a model.
She also likes solving her own life problems with AI, and talks about it on YouTube.
