This article is part of our coverage of the latest inAI research.
For humans, working with deformable objects is not significantly more difficult than handling rigid objects.
But for robots and artificial intelligence systems, manipulating deformable objects present a huge challenge.

Consider the series of steps that a robot must take to shape a ball of dough into pizza crusts.
It’s free, every week, in your inbox.
This is a problem that has been largely solved for rigid objects.

However, when it comes to deformable objects, the space of possible states becomes much more complicated.
Furthermore, the ways they deform are also harder to model in a mathematical way compared to rigid bodies.
The development of differentiable physics simulators enabled the program of gradient-based methods to solve deformable object manipulation tasks.

DiffSkill was inspired byPlasticineLab, a differentiable physics simulator that was presented at the ICLR conference in 2021.
PlasticineLab showed that differentiable simulators can help short-horizon tasks.
But differentiable simulators still struggle with long-horizon problems that require multiple steps and the use of different tools.
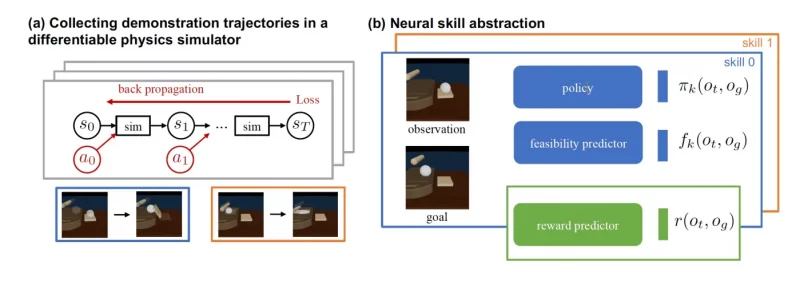
For DiffSkill, he chose dough manipulation because of the challenges it poses.
Once trained, DiffSkill can successfully accomplish a set of dough manipulation tasks using only RGB-D input.
DiffSkill uses a differentiable physics simulator to generate training examples for the skill abstractor.
These examples are presented to the skill abstractor as RGB-D videos.
Given an image observation, the skill abstractor must predict whether the desired goal is feasible or not.
The model learns and tunes its parameters by comparing its prediction with the actual outcome of the physics simulator.
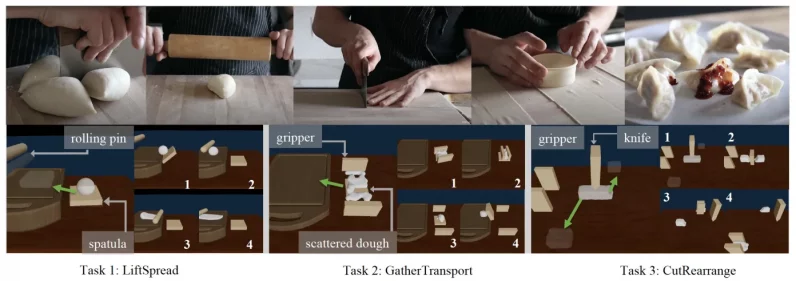
Robotic manipulation of deformable objects like dough requires long-horizon reasoning over the use of different tools.
This makes the VAE more stable when applied to the real world.
In fact, we are working on a follow-up project using point cloud as input.
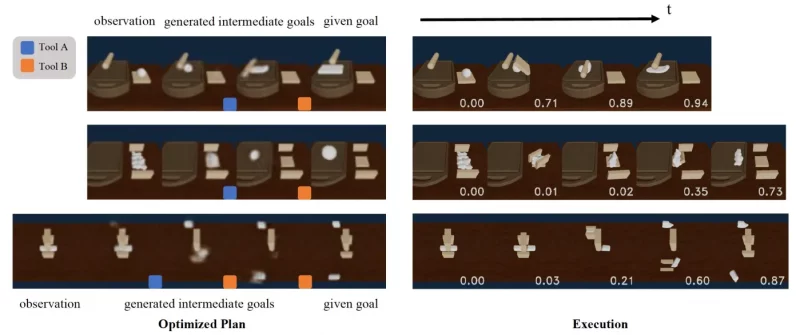
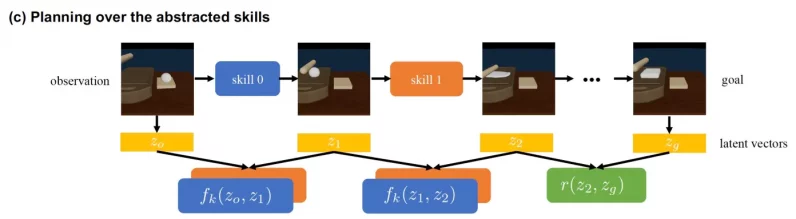
This planner iterates over possible combinations of skills and the intermediate outcomes they yield.
The variational autoencoder comes in handy here.
The models were tested on several tasks that require multiple steps and tools.
However, there are also limits to DiffSkills capacity.
Lin also mentioned that in some cases, the feasibility predictor produces false positives.
The researchers believe that learning a better latent space can help solve this problem.
Lin hopes that one day, he can use DiffSkill on real pizza-making robots.
We are still far from this.
Various challenges emerge from control, sim2real transfer, and safety.
But we are now more confident at trying some long-horizon tasks, he said.
you’re free to read the original articlehere.
