Last week, I wrote an analysis of Reward Is Enough, a paper by scientists at DeepMind.
Of course, both sides make valid claims.
But the truth lies somewhere in the middle.
Natural evolution is proof that the reward hypothesis is scientifically valid.
But implementing the pure reward approach to reach human-level intelligence has some very hefty requirements.
It’s free, every week, in your inbox.

Scientific evidence supports this claim.
Humans and animals owe their intelligence to a very simple law: natural selection.
In a nutshell, nature gives preference to lifeforms that are better fit to survive in their environments.

Those that can withstand challenges posed by the environment (weather, scarcity of food, etc.)
and other lifeforms (predators, viruses, etc.)
will survive, reproduce, and pass on their genes to the next generation.
Those that dont get eliminated.
According to Dawkins, In nature, the usual selecting agent is direct, stark and simple.
It is the grim reaper.
But there is something very crude and simple about death itself.
But how do different lifeforms emerge?
Every newly born organism inherits the genes of its parent(s).
But unlike the digital world, copying in organic life is not an exact thing.
These mutations can have a simple effect, such as a small change in muscle texture or skin color.
This advantage enabled it to better survive and reproduce.
As its descendants reproduced, those whose mutations improved their sight outmatched and outlived their peers.
The same self-reinforcing mechanism has also created the brain and its associated wonders.
However, when it comes to implementing this rule, things get very complicated.
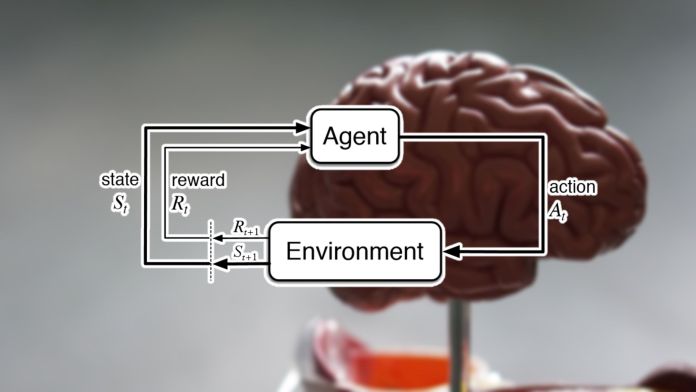
A reinforcement learning agent starts by making random actions.
Based on how those actions align with the goals it is trying to achieve, the agent receives rewards.
Across many episodes, the agent learns to develop sequences of actions that maximize its reward in its environment.
In reinforcement learning, the goal is to maximize an arbitrary reward signal.
DeepMind has a lot of experience to prove this claim.
They have also developed reinforcement learning models to make progress insome of the most complex problems of science.
This is where hypothesis separates from practice.
The keyword here is complex.
And they still required the financial backing and vast computational resources ofvery wealthy tech companies.
Now, imagine what it would take to use reinforcement learning to replicate evolution and reach human-level intelligence.
First, you would need a simulation of the world.
But at what level would you simulate the world?
My guess is that anything short of quantum scale would be inaccurate.
And we dont have a fraction of the compute power needed to create quantum-scale simulations of the world.
Lets say we did have the compute power to create such a simulation.
We could start at around 4 billion years ago, when the first life-forms emerged.
You would need to have an exact representation of the state of Earth at the time.
We would need to know the initial state of the environment at the time.
And we still dont have a definite theory on that.
At that time, there were millions of different lifeforms on Earth, and they were closely interrelated.
Taking any of them out of the equation could have a huge impact on the course of the simulation.
Therefore, you basically have two key problems: compute power and initial state.
The further you go back in time, the more compute power youll need to trigger the simulation.
On the other hand, the further you move forward, the more complex your initial state will be.
A behavior that maximises cleanliness must therefore yield all these abilities in service of that singular goal.
This statement is true, but downplays the complexities of the environment.
Kitchens were created by humans.
you might create shortcuts, such as avoiding the complexities of bipedal walking or hands with fingers and joints.
But then, there would be incongruencies between the robot and the humans who will be using the kitchens.
Language omits many important details, such as sensory experience, goals, needs.
We fill in the gaps with our intuitive and conscious knowledge of our interlocutors mental state.
We might make wrong assumptions, but those are the exceptions, not the norm.
But then you would be cheating on the reward-only approach.
In theory, reward only is enough for any kind of intelligence.
But in practice, theres a trade off between environment complexity, reward design, and agent design.
it’s possible for you to read the original articlehere.
