Did you knowNeural is taking the stage this fall?
Scientists are regularly finding new ways to attack and defend machine learning models.
The attacker starts with the unmodified image of a dog.

The class with the highest confidence score corresponds to the class to which the image belongs.
The modification results in a small change to the models output.
Adversarial attack algorithms usually have an epsilon parameter that limits the amount of change allowed to the original image.

The epsilon parameter makes sure the adversarial perturbations remain imperceptible to human eyes.
There are different ways to defend machine learning models against adversarial attacks.
However, most popular defense methods introduce considerable costs in computation, accuracy, or generalizability.

For example, some methods rely on supervised adversarial training.
It also isnt guaranteed to work against attack techniques that it hasnt been trained for.
This makes it difficult to employ these algorithms in applications where the explanation of algorithmic decisions is a requirement.
Candidate at Carnegie Mellon and lead author of the paper, told TechTalks.
The development of the defense takes place in multiple steps.
There are as many reconstructor networks as there are output classes in the target model.
Each reconstructor is anautoencoder web link.
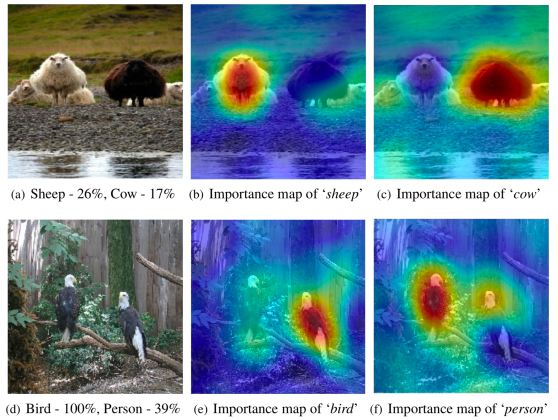
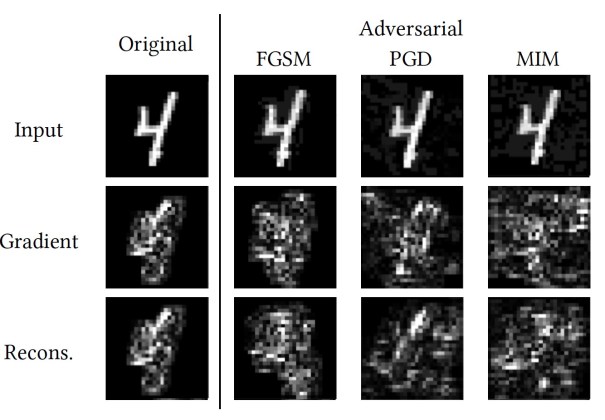
It takes an image as input and produces its explanation map.
This allows the inspector to detect and flag adversarially perturbed images.
Experiments by the researchers show that abnormal explanation maps are common across all adversarial attack techniques.
In contrast, our unsupervised method is computationally better as no pre-generated adversarial examples are needed.
you’ve got the option to read the original articlehere.
