You know that expressionWhen you have a hammer, everything looks like a nail?
You might say theyre more than meets the… ugh, forget it.
A Transformer is a pop in of neural online grid architecture.
But there are different types of neural networks optimized for different types of data.
For example, for analyzing images, well typically useconvolutional neural networksor CNNs.
Vaguely, they mimic the way the human brain processes visual information.
That was unfortunate, because language is the main way we humans communicate.
It’s free, every week, in your inbox.
Lets say you wanted to translate a sentence from English to French.

The key word here is sequential.
In language, the order of words matters and you cant just shuffle them around.
The sentence:
Jane went looking for trouble.
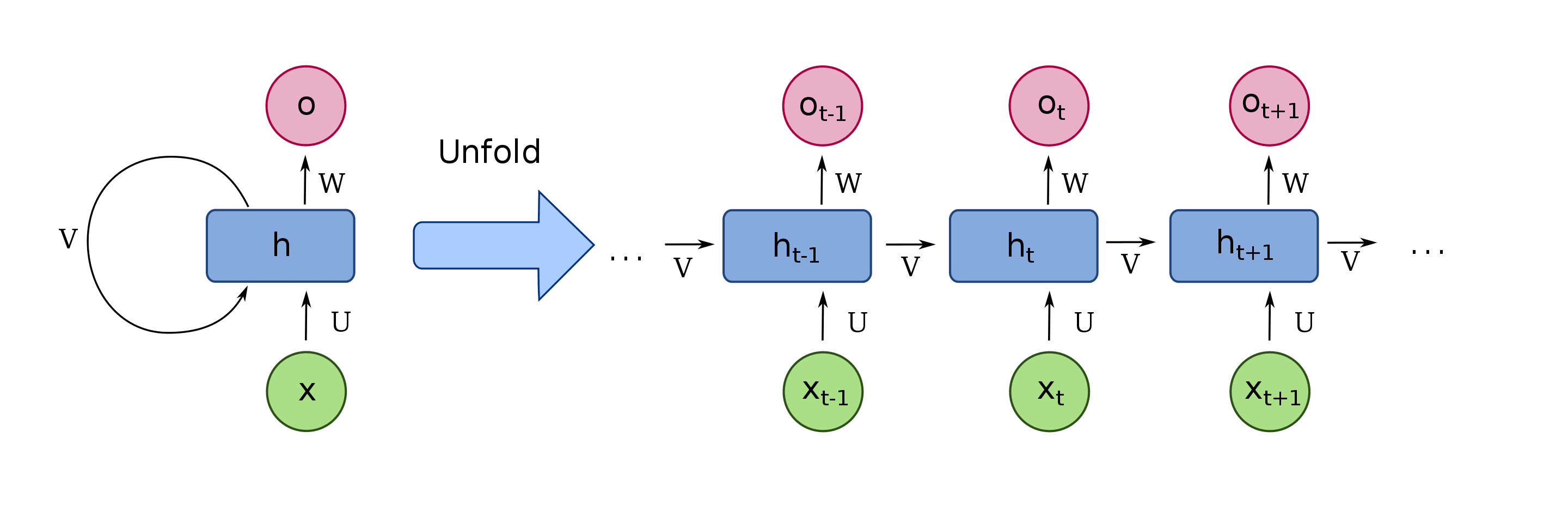
But RNNs had issues.
First, they struggled to handle large sequences of text, like long paragraphs or essays.
By the time got to the end of a paragraph, theyd forget what happened at the beginning.
Worse, RNNs were hard to train.
Even more problematic, because they processed words sequentially, RNNs were hard to parallelize.
Enter Transformers
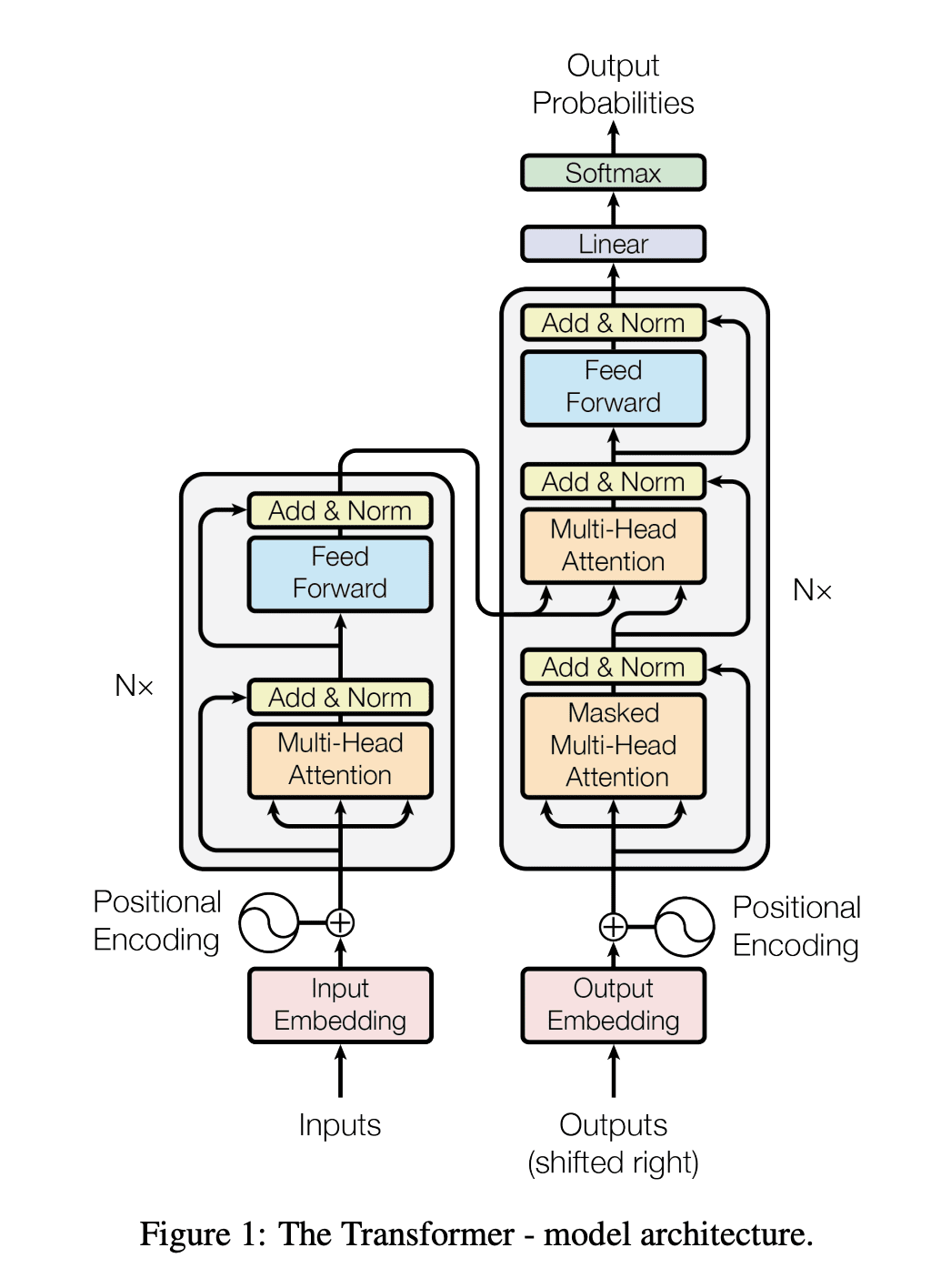
This is where Transformers changed everything.

But unlike recurrent neural networks, Transformers could be very efficiently parallelized.
And that meant, with the right hardware, you could train some really big models.
How do Transformers work?
Lets say were trying to translate text from English to French.
Remember that RNNs, the old way of doing translation, understood word order by processing words sequentially.
But this is also what made them hard to parallelize.
Transformers get around this barrier via an innovational called positional encodings.
Store word order as data, not structure, and your neural connection becomes easier to train.
Attention
THE NEXT IMPORTANT PART OF TRANSFORMERS IS CALLED ATTENTION.
Attentionwas introduced in the context of translation two years earlier, in 2015.
Also, French is a language with gendered words.
The adjectives economique and europeenne must be in feminine form to match the feminine object la zone.
And how does the model know which words it should be attending to at each time step?
Its something thats learned from training data.
It learns how to respect gender, plurality, and other rules of grammar.
So, the innovation of the 2017 Transformers paper was, in part, to ditch RNNs entirely.
Thats why the 2017 paper was called Attention isallyou need.
For example, take these two sentence:
Server, can I have the check?
Looks like I just crashed the server.
Self-attention allows a neural data pipe to understand a word in the context of the words around it.
In the second sentence, the model might attend to the word crashed to determinethisserver refers to a machine.
So, here we are.
What Can Transformers Do?
One of the most popular Transformer-based models is called BERT, short for Bidirectional Encoder Representations from Transformers.
How can I use Transformers?
you’re able to download common Transformer-based models like BERT fromTensorFlow Hub.
For a code tutorial, check outthis oneI wrote on building apps powered by semantic language.
